Why Your Data Science Notebook Will Break in Production (And How to Fix It)
Published: October 2025
By Amy Humke, Ph.D.
Founder, Critical Influence
Most new data scientists start their journey in a notebook. You import, load data, clean it up, train a model, check the scores, and hit "run" whenever you feel like updating it. That's perfect for exploration. But Production is an entirely different game. A pipeline takes that same logic and turns it into something repeatable, trackable, and safe. It's the difference between saying, "I got it to work once," and "it works every day, on schedule, without breaking anything." In a production system, you can't just re-run the whole notebook when one thing changes. If you're moving your machine learning model into a pipeline for the first time, this is the simple explanation I wish I'd had on day one.
The Core Idea: Two Production Lines
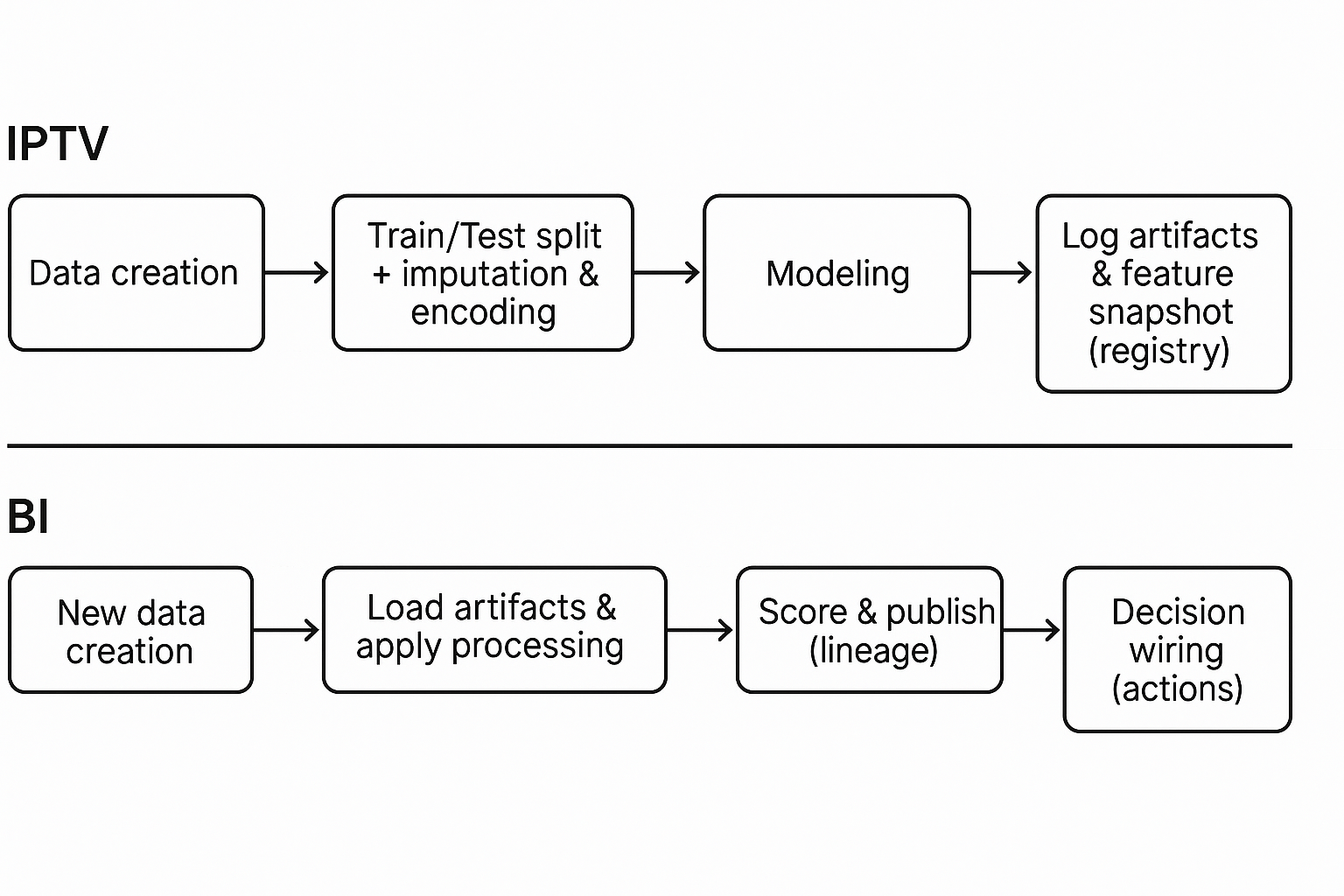
The secret to a reliable system is the separation of duties. You need two different, distinct "notebook chains" or lines of work: one for building the model, and one for running the model daily.
1. The "Recipe Maker" Line (IPTV)
This line does the heavy lift and runs only when you need to retrain or change your model's logic.
What it is: The Input, Prepare, Transform, Validate line.
Its Job: Ingest the raw data, clean it, transform it into the final features your model uses, train the model, and validate the results.
The Output: Its main job is to create a clean, versioned feature snapshot and a whole bundle of artifacts (we'll explain those next). This becomes the one accurate reference for the production environment.
Two Critical Rules:
- Temporal Honesty: Features are computed only from data available up to the time of the event. No "looking ahead." If you accidentally provide the model with data from the future, it will be a genius in testing but a disaster in Production.
- Schema Discipline: The input and output data must stick to a predefined contract (names, types, no unexpected missing values). If the data shifts, the job must stop and alert you.
2. The "Line Cook" Line (BI)
This is the production run line, which applies the model on a scheduled basis (daily, hourly).
What it is: The Business Inference line.
Its Job: To be boring. It pulls in the newest data, loads the most recent artifact bundle from the Recipe Maker, applies the model as-is, scores the new rows, and writes a tidy record with a clear paper trail (lineage).
No Refitting! The Line Cook never adjusts the recipe. It loads the exact averages, mappings, and scaling parameters saved during training. If it had to guess, your scores would slowly drift into trouble.
Stopping is a Feature: If the new data doesn't match the quality or structure that the Recipe Maker was trained on (e.g., a required column is missing), the job should pause and send an alert. It should use the last valid score and clearly mark it. This is intentional; it protects you from publishing bad numbers.
What "Artifacts" Really Are
If your production scoring process has to "guess" anything, you will fail.
Artifacts are the model's entire memory. Think of them like a Pantry of ingredients and tools that the Line Cook must use to replicate the dish perfectly.
Everything the model depended on gets saved and versioned together:
- The model file and the data shape it expects.
- The Imputation values (e.g., the average salary) are used to fill in missing data.
- All encoders and mapping dictionaries (e.g., how you converted 'CA' to the number '5').
- Any scaler or normalizer settings are used to adjust the ranges of your features.
- A configuration file that tells the Line Cook exactly how to use this bundle.
You tag all of this with a version (e.g., model_v2.1, training_data_2025-06-01). When someone asks, "Why did the score change today?" you can point to a versioned artifact, not a memory. One place. One truth.
Treating Your Code Like King (GitHub and CI/CD)
Your system needs a backbone that enforces rules and enables safe changes. GitHub is the manual.
GitHub (or a similar version control) should be the single source of truth for all production code, configurations, and schedules. If a new teammate can't find the entry points and schedules easily, your setup is too complicated.
You should separate Development, Staging, and Production environments.
- Development: For quick changes and feedback.
- Staging: Used to verify a change works just like Production, but without risking real outputs.
- Production: Where the system serves the business. Changes here must be slow, reviewed, and easy to undo.
CI/CD: The Head Chef and the Pass
Continuous Integration (CI) and Continuous Delivery (CD) are your system's safety net:
- CI Prevents Drama: On every code change (Pull Request), CI runs unit tests for your transformations, checks the data contract (schema), and runs security scans. If any gate fails, nothing moves. CI proves the change is safe in theory.
- CD Promotes Safely: When you launch a new model, CD handles the promotion flow. It should start with a canary test, running the latest model on a tiny slice of live data. If it holds, it will be promoted to full Production. If it fails, you hit the easy rollback button by re-pointing the Line Cook to the previous, working artifact version.
Planning for Failure (Because It Always Happens)
Backfill Without Starting Over
Your data will fail. When it does, you can't afford to re-run the entire Recipe Maker for every partition since the beginning of time.
- Partition Data: Store your features and scores immutably (unchangeable) by event date.
- Backfill Smart: When you need to reprocess the data from June 1st, you only run the Line Cook (BI) for June 1st, using the original artifacts. This avoids the costly "recompute everything" tax.
- Checkpointing: If a daily job fails halfway, it needs to be able to resume from the last safe point. This keeps outputs tidy and cuts re-run time.
Monitoring That Triggers Action
You're not monitoring to create a nice dashboard; you're monitoring to prevent a crisis.
- Input Drift: Is the new production data starting to look significantly different from the training data? (e.g., the distribution of one feature has completely shifted).
- Output Performance: Once you get a true label, is your model's accuracy, log loss, and fairness suddenly slipping)?
When drift or performance slips past a set threshold, the system should alert and, in some cases, automatically trigger the Recipe Maker (IPTV) to retrain.
The Newcomer's Mental Model
Think of your MLOps pipeline like a professional, high-volume restaurant:
| Pipeline Component | Restaurant Equivalent | Core Function |
|---|---|---|
| IPTV Line | The Recipe Maker (Chef) | Writes the perfect recipe once; saves the exact ingredients and oven settings. |
| Artifacts | The Pantry. | Everything the kitchen needs is labeled, versioned, and on the right shelf. |
| BI Line | The Line Cook | Same dish. Same steps. Every night. Gets the ticket out on time. |
| CI/CD | The Pass & Head Chef | Checks the quality of every dish, sends back any bad plates, and updates the menu only when the test table gives the green light. |
| Monitoring | the Post-Service Taste Test | If the quality is slipping, you pull the lever to retrain the recipe. |
If you maintain that separation cleanly, you achieve consistency without needing to babysit.
Tips That Save Reputations
- Never use the word 'latest.' Pin specific versions for everything.
- Keep BI pure. No fitting, no recalculating averages, no model tuning in Production. Ever.
- Store mappings and calibration separately so BI can load them directly.
- Write lineage every time. You will need to know who produced what number and when.
- Design for carry forward up front. A wrong score that appears 'fresh' hurts more than a stale score that is clearly flagged as delayed.
- Treat backfill as a product, not a one-off notebook.
- Add guardrails for cost and cardinality. Join blowups will eat your lunch.
- Don't ship a dashboard until the action is wired. Pretty is not Production.
- If a score is not wired to change a decision, it is not ready for the Line Cook.
Conclusion
Ultimately, the goal isn't to make your life harder; it's to eliminate repetitive manual work and protect the integrity of the model. By cleanly separating the Recipe Maker (IPTV) from the Line Cook (BI), you build a system that achieves consistency without needing constant human intervention. Trust in your model comes from knowing exactly what produced a score, when it was produced, and why. That is the value of moving from a notebook to a pipeline: predictable, traceable, and repeatable machine learning that actually serves the business.